De Hogeschool Utrecht begint, in afstemming met de NIMA, met een nieuwe Masterclass Marketing Analytics. Deze is bedoeld voor professionals die werkzaam zijn op het terrein van marketing, communicatie en/of customer experience en die meer willen weten over hoe om te gaan met data, welke data je voor welke marketingbeslissing nodig hebt, hoe dit te organiseren en te structuren en hoe je dit kunt doorgronden. Register Marketeer en marketingwetenschapper Ronald Voorn legt uit waarom die masterclass er moest komen aan de hand van de presentatie die hij bijwoonde op de NIMA Marketing Day.
Door Ronald Voorn
Bedrijven hebben niets aan big data. Het gaat om de inzichten daaruit! Ik moest even aan deze uitspraak denken toen ik zat te kijken naar de zeer interessante presentatie van Wiemer Snijders en Robert van Ossenbruggen van The Commercial Works op de (weer fantastische) NIMA Marketing Dag. Zij lieten daar een mooie grafiek met staafdiagrammen zien die aangaf hoeveel bedrijven verdienen aan hun klanten (op de verticale as). De (big) dataset die ze presenteerden bevatte het koopgedrag van iets minder dan 2 miljoen mensen over een periode van 1 jaar.
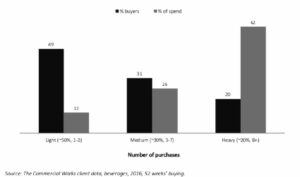
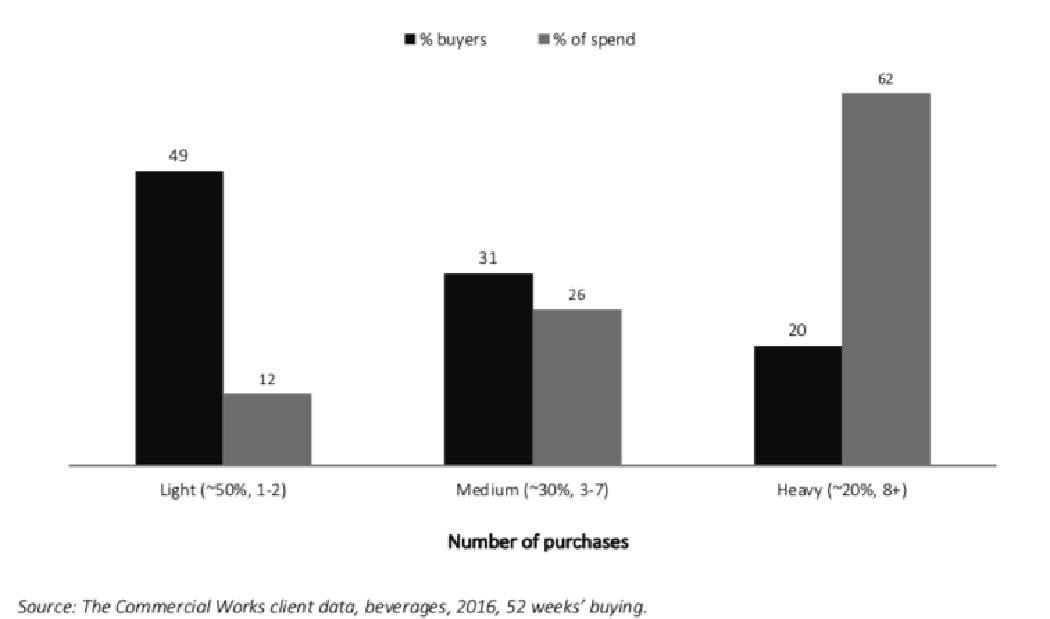
Op de horizontale as was dan van links naar rechts de mate van licht tot zwaar gebruik te zien. Uiteraard was daar een relatie tussen en was de hoogste staaf met geld zichtbaar bij de heavy users die zich rechts van de horizontale as bevonden. Vervolgens was de vraag in welke van de groepen gebruikers nu het beste geïnvesteerd kon worden. Heel voorspelbaar riep de grootste groep in de zaal “rechts natuurlijk”. Op het eerste oog lijkt dat ook de juiste conclusie, de heavy users brachten in dit geval circa vijf keer meer omzet binnen. Het probleem is echter dat deze gebruikelijk manier van rapporteren een misleidend beeld geeft van wie je belangrijkste klanten zijn; een (denk)fout die een merk duur kan komen te staan…
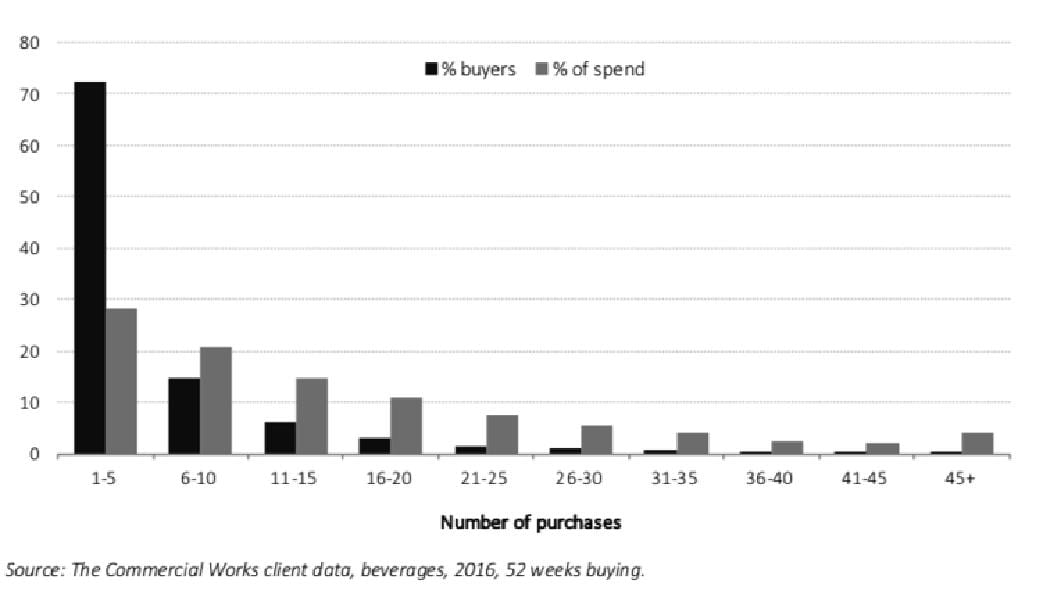
Want vervolgens lieten Wiemer en Robert de exact zelfde dataset zien. Die had nu ineens de vorm van een banaan (de statistisch correcte naam voor deze verdeling is de Negatief Binomiale Distributie, maar de vergelijking met een banaan werd expres gemaakt zodat mensen het makkelijker konden onthouden). Weer stond de mate waarin men het product gebruikte op de horizontale as uitgezet als frequentie met van links (lichte gebruikers) naar rechts (heavy users), maar ditmaal veel fijnmaziger.

Andrew Ehrenberg was de eerste wetenschapper die dit patroon in 1959 beschreef en sindsdien heeft men in 60 jaar wetenschappelijk onderzoek nog geen afwijking op dit patroon in ons koopgedrag gevonden. En dan zie je pas waar de echte groei zit en dat is in het linkerdeel van de banaan. Daar zijn gewoon meer mensen. Dus penetratieverhoging is een veel interessantere groeistrategie dan de heavy users proberen aan te zetten tot nog eens meer Coke Light- of Dreft-gebruik. Zo zie je dat data pas interessante en bruikbare informatie oplevert als je er goed naar leert kijken.
Maar hoe leer je dat dan?
Aangezien het steeds belangrijker wordt om data goed te leren begrijpen moet je bijblijven. Daarvoor zijn geschikte cursussen nodig die speciaal geschikt zijn voor mensen die al een baan hebben. De Hogeschool Utrecht begint daarom, in afstemming met de NIMA, op 17 september as. met een nieuwe Masterclass Marketing Analytics. Deze is bedoeld voor professionals die werkzaam zijn op het terrein van marketing, communicatie en/of customer experience en die meer willen weten over hoe om te gaan met data, welke data je voor welke marketing beslissing nodig hebt, hoe dit te organiseren en te structuren en hoe je dit kunt doorgronden.
In zeven modules van 6 uur ga je samen met andere praktijkgenoten hands-on zelf aan de slag met state-of-the-art data-analyses die vandaag de dag gebruikt worden in moderne organisaties om betere marketingbeslissingen te nemen. Denk hierbij bijvoorbeeld aan segmentatie analyses, conversie-attributie en customer journey analyses. In de modules word je daarnaast zelf aan het werk gezet aan de hand van praktijkopdrachten, onderzoek en literatuur. Natuurlijk ga je ook zelf aan de gang om een dataset te leren begrijpen met het gebruik van machine learning en Artificial Intelligence.
Programma
In het programma komen qua theorie en aan de hand van een doorlopende praktijkcase o.a. de volgende onderwerpen aan bod:
- Cross-industry standard process for data mining
- Introductie en overzicht van data analytics
- Segmenteren en doelgroepen clusteren
- Conversie-attributie
- Churn voorspellingen en customer lifetime value bepaling
- Social Network Analysis
- Customer Journey analyse
- Product Recommendations
Docenten
De colleges worden voor een groot deel verzorgd door docenten uit het bedrijfsleven. Dit keer zijn dat Kevin van Kalkeren MSc (data scientist bij OnMarc) en Ludo Voorn MM RM (eigenaar Marketing Transformers). Hierdoor sluit de inhoud steeds naadloos aan op de (complexe) vraagstukken uit de hedendaagse markt. Inhoudelijk is de opleiding nauw verbonden met verschillende lectoraten van de Hogeschool Utrecht in het betreffende onderzoeksgebied en mede daardoor van hoog niveau. NIMA leden kunnen 30 PE Punten behalen met deelname aan de cursus. Voor meer informatie kun je contact opnemen met Mieke Braadbaart: mieke.braadbaart@hu.nl.